
Página
Tema 4.1 - Recapitulemos
Recapitulemos
En la última misión, exploramos cómo usar un modelo de aprendizaje automático k-nearest neighbors simple que usó solo una característica, o atributo, de la lista para predecir el precio de renta, primero nos basamos en la columna de accommodates, que describe el número de personas que un espacio habitable puede acomodar cómodamente, luego, cambiamos a la columna de bathrooms y observamos una mejora en la precisión, si bien estas fueron buenas características para familiarizarse con los conceptos básicos del aprendizaje automático, está claro que usar una sola característica para comparar listados no refleja la realidad del mercado, un apartamento que puede acomodar a 4 personas en una parte popular de Washington D.C. se alquila por mucho más alto que uno que puede acomodar a 4 personas en un área plagada de delitos.
Hay 2 formas en las que podemos retocar el modelo para tratar de mejorar la precisión (mejorar el RMSE durante la validación):
- Incrementar el número de atributos que el modelo usa para calcular similitudes cuando ranquea los vecinos más cercanos
- Incrementar k, el número de vecinos cercanos que el modelo usa cuando calcula la predicción
En esta misión, nos centraremos en aumentar el número de atributos que utiliza el modelo, al seleccionar más atributos para utilizar en el modelo, tenemos que tener cuidado con las columnas que no funcionan bien con la ecuación de la distancia, esto incluye las columnas que contienen:
-
Valores no numéricos (por ejemplo, ciudad o estado):
- La ecuación de distancia euclidiana espera valores numéricos
- Valores perdidos:
- La ecuación de la distancia espera un valor para cada observación y atributo
-
Valores no ordinales (por ejemplo, latitud o longitud):
- La clasificación por distancia euclidiana no tiene sentido si todos los atributos no son ordinales
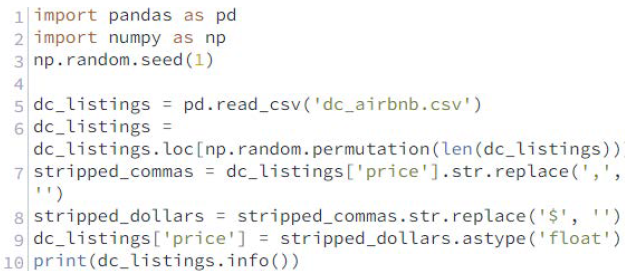
En la siguiente pantalla de código, hemos leído el conjunto de datos dc_airbnb.csv de la última misión en pandas y hemos traído los cambios de limpieza de datos que hicimos, vamos a ver primero los valores de la primera fila para identificar cualquier columna que contenga valores no numéricos o no ordinales, en la siguiente pantalla, eliminaremos esas columnas y luego buscaremos los valores que faltan en cada una de las columnas restantes.
Instrucciones
- Utilice el método DataFrame.info() para devolver el número de valores no nulos en cada columna
Soluciones
|
|
Última modificación: miércoles, 27 de abril de 2022, 18:08