
Página
Tema 4.10 - Utilización de Todas las Funciones
Utilización de Todas las Funciones
Hasta aquí todo bien, a medida que aumentamos las características que utiliza el modelo, observamos valores de MSE y RMSE más bajos:
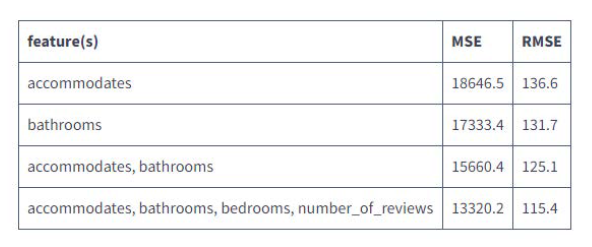
Llevemos esto al extremo y utilicemos todas las características potenciales. Deberíamos esperar que las puntuaciones de error disminuyan, ya que hasta ahora añadir más características ha ayudado a hacerlo.
Instrucciones
- Utilice todas las columnas, excepto la de precio (price), para entrenar un modelo de vecinos más cercanos utilizando los mismos parámetros para la clase KNeighborsRegressor que los de las últimas pantallas
- Utilice el modelo para realizar predicciones en el conjunto de pruebas y asigne la matriz NumPy resultante de predicciones a all_features_predictions
- Calcule los valores MSE y RMSE y asígnelos a all_features_mse y all_features_rmse
- Utilice la función de impresión (print) para mostrar ambas puntuaciones de error
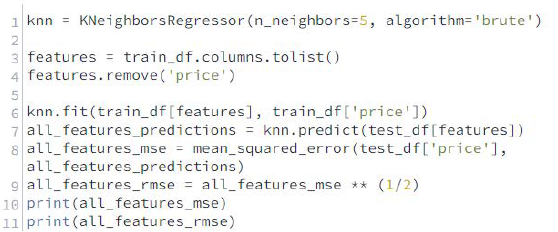
Soluciones
|
|
|
-
Curiosamente, el valor del RMSE aumentó hasta 125,1 cuando utilizamos todas las características disponibles, esto significa que la selección de las características adecuadas es importante y que el uso de más características no mejora automáticamente la precisión de la predicción, deberíamos reformular la palanca que mencionamos antes de:
- Aumentar el número de atributos que el modelo utiliza para calcular la similitud al clasificar a los vecinos más cercanos a:
- Seleccione los atributos relevantes que el modelo utiliza para calcular la similitud al clasificar a los vecinos más cercanos
- El proceso de selección de las características que se utilizarán en un modelo se conoce como selección de características
-
En esta misión, preparamos los datos para poder utilizar más características, entrenamos algunos modelos utilizando múltiples características y evaluamos las diferentes compensaciones de rendimiento, hemos explorado cómo el uso de más características no siempre mejora la precisión de un modelo de, en la próxima misión, exploraremos otro botón para ajustar los modelos de k-nearest neighbors: el valor de k.
Última modificación: miércoles, 27 de abril de 2022, 23:25