
Página
Tema 2.1 - Métricas de evaluación problemas de clasificación
Resumen
Métricas de evaluación o métricas de error
Nos permitirán conocer el desempeño de nuestro modelo de ML. Al momento de evaluar los algoritmos de clasificación es fundamental diferenciar entre una clasificación binaria o multiclase. Una de las métricas más usadas es la matriz de confusión que nos suministra información sobre qué tipos de aciertos y errores está teniendo nuestro modelo a la hora de pasar por el proceso de aprendizaje con los datos. A partir de la matriz de confusión se pueden obtener métricas como acurracy, sensivity/specificity, precision/recall y f-measure.
En la práctica lo habitual es mantener dos vectores de datos. Por un lado, un vector que contiene la verdad o los valores observados y otro vector que contiene los valores predichos o estimados. Ambos vectores deben tener el mismo tamaño.
La clase verdadera se conoce de antemano y esta variable se utiliza para evaluar el algoritmo en el conjunto de test comparándola con el resultado predicho.
Los valores predichos se obtienen por medio de la aplicación de un modelo sobre el conjunto de test.
Error de clasificación:
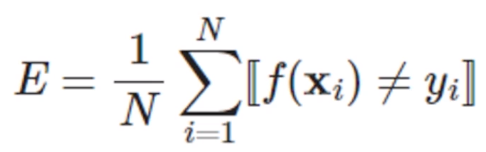
Donde [[.]] es una función indicadora que es igual a 1 cuando la condición se cumple, de lo contrario, es igual a 0.
Última modificación: martes, 3 de enero de 2023, 13:28