
Página
Tema 1.5 - Conclusiones reto de clasificación
Resumen
Una vez obtenidos los resultados deberá realizar un análisis de los mismos y definir claramente cuál es el mejor modelo según el problema.
Primero que todo, debemos definir el criterio por el cual se va a escoger el mejor modelo y este está dado por la naturaleza mismas del problema, nos interesa construir un modelo que sea bueno prediciendo ambas clases (comprara / No comprara), sin embargo, dado que el dataset se encuentra desbalanceado no podemos usar la métrica de accuracy como métrica global, debemos mirar la capacidad de predicción para ambas clases y escoger el modelo que tenga el mejor comportamiento.

Tabla con los resultados:
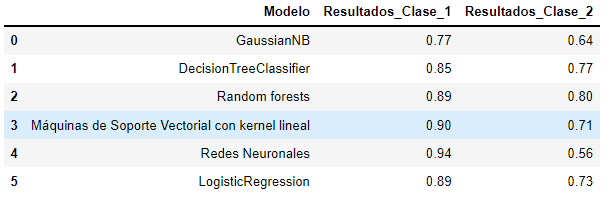
Conclusión:
Como se logra apreciar, el modelo que tiene los mejores resultados clasificando ambas clases es el Random forests porque logra un 90% de clasificación correcta para la clase 1 (No compro) y un 80% de clasificación correcta para la clase 2 (Compro), si solo nos hubiéramos limitado a escoger el mejor modelo por el Accuracy este sería la Rede Neuronal artificial, sin embargo, vemos que esta comete muchos errores clasificando la clase 2 (Compro), por lo tanto, es importante saber definir el criterio para seleccionar el mejor modelo y esto dependen netamente del problema que estemos abordando.
Última modificación: viernes, 20 de enero de 2023, 18:16