
Página
Tema 1.2 - Conceptos de Calidad & Metodologías de Desarrollo para pruebas unitarias
Pirámide de pruebas de Cohn
En este punto ya tenemos claros los conceptos acerca de las pruebas unitarias, características de calidad y algunas de sus ventajas; es entonces hora de hablar sobre el orden y proporción en la que se crean y ejecutan las pruebas y para ello veremos la pirámide de Testing o también conocida pirámide de pruebas de Cohn.
Esta pirámide está compuesta por varios niveles que, desde su base hacia arriba, indica el orden y proporción en el que se deberían generar las pruebas.
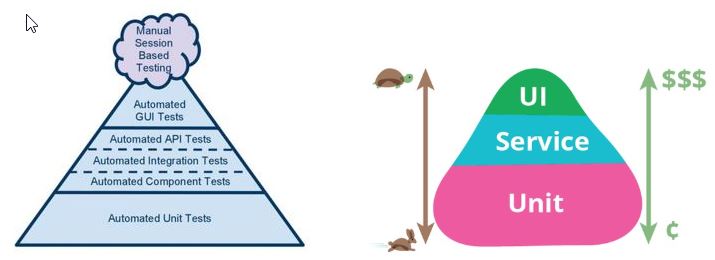
La figura anterior, representa la manera “ideal” de distribuir las pruebas automáticas de un sistema en sus diferentes capas:
- El ancho indica la proporción de pruebas que deberían existir en relación a los diferentes niveles.
- La altura indica la velocidad y facilidad de mantenimiento.
De acuerdo a lo anterior, podemos deducir que se recomienda tener una mayor cantidad de pruebas unitarias, las cuales como ya hemos visto se ejecutan de forma muy rápida y su mantenimiento es muy puntual (se recomienda que el 70% sean unitarios), en segunda instancia, se recomienda tener un gran número de pruebas que apunten a la lógica del negocio (Componentes, Integración y APIs), estás tienen la particularidad que apuntan directamente a la lógica del negocio y aunque no son tan rápidas como las pruebas unitarias, si suelen ser mas rápidas que las pruebas a nivel de interfaz de usuario (se recomienda que el 20% sean test a este nivel), y por último, tendríamos las pruebas a nivel de la interfaz, ya que en los niveles anteriores se han depurado la gran parte de los defectos, de manera que el foco de estas pruebas debería ir dirigido a temas de look & feel, UI, y similares (el 10% restante de los test).
Lo anterior quiere decir que, al tener estas pruebas automatizadas en los diferentes niveles, los analistas de calidad pueden disponer su tiempo en la ejecución de pruebas exploratorias de nuevos escenarios o funcionalidades.
Ahora, es importante tener presente que cuando hablamos de pirámide de pruebas al mismo tiempo o de manera implícita, se está haciendo referencia que estás pruebas son automatizadas.
¿Y por qué la Pirámide de Cohn?
Para responder esta pregunta es importante remontarnos al modelo de pruebas del cono de helado, que básicamente es la pirámide de pruebas, pero invertida, es decir, pocas pruebas unitarias, algunas más a nivel de la lógica del negocio (Componentes, Integración y APIs) y en su gran mayoría pruebas de interfaz de usuario.

Este modelo como tal tenía como finalidad “Hallar defectos”, ya que desde la interfaz de usuario se esperaba encontrar defectos que no habían sido cubiertos en los niveles inferiores y por ende las pruebas eran muy tediosas sin mencionar que la calidad de los productos no era la mejor. En comparación, es evidente que desde etapas tempranas en el modelo de la pirámide de Cohn, las pruebas están enfocadas no a la búsqueda de defectos, sino a prevenir su generación.
Hay algunos otros modelos como el reloj de arena, el cual en sus extremos es amplio y angosto en su centro, es decir, se cuenta con gran proporción de pruebas unitarias y de interfaz gráfica y pocas pruebas a nivel de componente, integración y APIs.
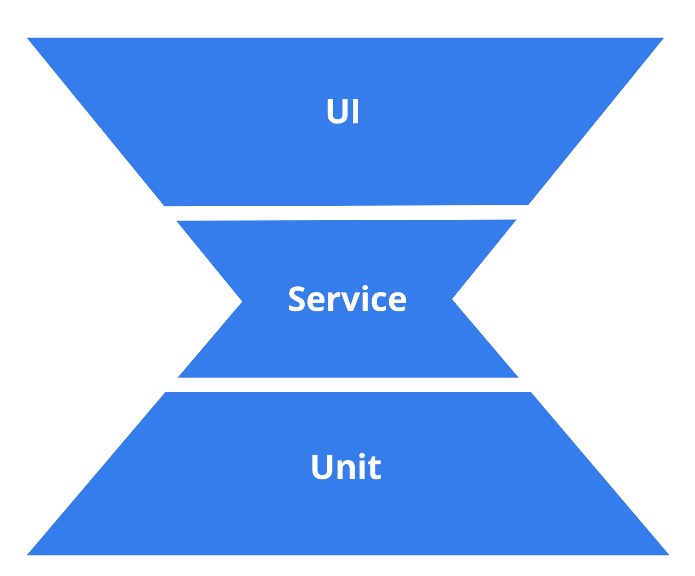
Y aunque es una mejora respecto al modelo del cono de helado siguen existiendo problemas fundamentales en estos dos modelos y son:
- La falta de colaboración y comunicación entre las áreas de QA y Desarrollo.
- Muchos test a nivel de interfaz de usuario hacen que la suite de pruebas de regresión sea lenta, disminuyendo la productividad del equipo y haciendo que la retroalimentación para los desarrolladores tome más tiempo.
- Los test a nivel de Interfaz son muy costos de mantener. Esto se debe a la gran cantidad de capas (red, navegadores, bases de datos, tecnologías de UI, etc…) que deben ser cubiertas por estas pruebas, así como factores externos como latencia y cambios constantes en la UI.
Metodología TDD (Test Driven Development)
Cuando se habla de pruebas unitarias es necesario hablar de TDD (Driven Development – Desarrollo Guiado por Pruebas), una metodología de desarrollo e implementación de software enfocada a la calidad por medio de la cobertura de pruebas unitarias.
Como vimos anteriormente, la cobertura de pruebas es un indicador de la cantidad de código que está sometido a nuestras pruebas, es decir, a una mayor cobertura mayor cantidad de código está siendo probado por nuestras pruebas unitarias.
Dependiendo de cada proyecto / organización se definen los Quality Gates o límites bajo los cuales se determinan los valores mínimos aceptables; aunque se podría decir que una cobertura de pruebas del 70% es un valor aceptable, que brinda cierta confianza respecto a la calidad que tiene el código gracias a las pruebas unitarias; es importante destacar que este porcentaje no indica que tengamos una buena calidad de pruebas, por lo tanto, no debe ser un valor en el que fijarse únicamente.
Con base a lo anterior, pasaremos a explicar la metodología TDD bajo la cual se crean las pruebas unitarias.

El desarrollo guiado por pruebas se compone de 3 fases principales:
1. Creación de las pruebas unitarias
2. Desarrollo del código del software de tal manera que éste satisfaga las pruebas unitarias anteriormente creadas.
3. Refactorización del código
Se elige el requisito que pensamos que nos dará mayor conocimiento del problema y que a la vez sea fácil su implementación; se comienza escribiendo una prueba para el requisito, necesitamos que las especificaciones y los requisitos de la funcionalidad que están por implementar sean claros. Este paso fuerza al programador a tomar la perspectiva de un cliente considerando el código a través de sus interfaces.
Una vez finalizada la codificación de la prueba unitaria, ésta al ser ejecutada obligatoriamente deberá fallar porque el código de este requerimiento aún no ha sido creado. A continuación, se procede a escribir el código más sencillo posible, que haga que la prueba funcione. Se ejecutan las pruebas para verificar si todo el conjunto de pruebas funciona correctamente. Y por último se procede con la refactorización, que se utilizará principalmente para eliminar código duplicado, eliminar dependencias innecesarias, etc.
Para que un test unitario sea útil y esta metodología tenga éxito, previamente a comenzar a codificar, es necesario cumplir los siguientes puntos:
- Tener bien definidos los requisitos de la función a realizar.
- Criterios de aceptación, contemplando todos los casos posibles, tanto exitosos como de error.
- ¿Qué se quiere probar?
- Tener claro el diseño de la prueba a realizar.
Ventajas
- Nos ayuda a pensar en cómo queremos desarrollar la funcionalidad.
- Puede hacer software más modular y flexible.
- Aumenta la confianza del desarrollador a la hora de introducir cambios en la aplicación.
Desventajas
- A veces se crean test innecesarios que provocan una falsa sensación de seguridad.
- Los test también hay que mantenerlos a la vez que se mantiene el código, lo cual genera un trabajo extra.
- Es difícil introducir TDD en proyectos que no han sido desarrollados desde el principio con TDD.
- Para que sea realmente efectiva hace falta que todo el equipo de desarrollo haga TDD.
Como se puede apreciar, el ciclo de vida de TDD se basa en una continua codificación y refactorización. A continuación, nos adentraremos un poco más en el proceso de desarrollo de una prueba unitaria y veremos a nivel estructural cómo debe ser implementada una prueba unitaria y un compendio de prácticas no recomendadas o anti-patrones.
Patrón de Test Unitario (Patrón AAA)
El patrón es un proceso de 3 pasos ampliamente aceptado como la forma de escribir pruebas unitarias. El patrón sugiere dividir una prueba unitaria en tres secciones, donde cada una de ellas tiene un cometido:
Arrange (Organizar): Este es el primer paso de una prueba unitaria. Aquí organizaremos la prueba, en otras palabras, haremos la configuración necesaria de la prueba. Por ejemplo, para realizar la prueba necesitamos crear un objeto de la clase objetivo (SUT), si es necesario, entonces necesitamos crear objetos simulados y otras inicializaciones variables.
Act (Actuar): Este es el paso intermedio de una prueba unitaria, en donde se ejecuta el código que llama al método que estamos probando (verificando). En este apartado, es donde se pasan los parámetros de entrada al método y donde se recoge el resultado devuelto por éste.
Assert (Afirmar): Este es el último paso de una prueba unitaria. En este paso, se realiza una comparación entre el resultado obtenido contra el resultado esperado (Verificación).
Veamos un ejemplo sencillo, de la clase “Calculadora.java” y sus pruebas unitarias:package com.calculadora.aaa; public class Calculadora { public int suma(int numeroUno, int numeroDos) { return (numeroUno+numeroDos); } public int resta(int numeroUno, int numeroDos) { return (numeroUno-numeroDos); } public int multiplicacion(int multiplicando, int multiplicador) { return (multiplicando*multiplicador); } public int division(int dividendo, int divisor) { return (dividendo/divisor); } }
package com.calculadoraTest.aaa; import static org.junit.jupiter.api.Assertions.*; import org.junit.jupiter.api.Test; import com.calculadora.aaa.Calculadora; class CalculadoraTest { @Test void testSuma() { //Arrange int resultado = 0; Calculadora adicion = new Calculadora(); //Act resultado= adicion.suma(1, 3); //Assert assertEquals(4, resultado); } @Test void testResta() { //Arrange int resultado = 0; Calculadora sustraccion = new Calculadora(); //Act resultado= sustraccion.resta(3, 1); //Assert assertEquals(2, resultado); } @Test void testMultiplicacion() { //Arrange int resultado = 0; Calculadora producto = new Calculadora(); //Act resultado= producto.multiplicacion(3, 2); //Assert assertEquals(6, resultado); } @Test void testDivision() { //Arrange int resultado = 0; Calculadora fraccion = new Calculadora(); //Act resultado= fraccion.division(6, 2); //Assert assertEquals(3.0, resultado); } }
Anti patrones de pruebas unitarias
A la hora de hablar de anti-patrones debe haber al menos dos elementos clave presentes para distinguir formalmente un anti-patrón real de un simple mal hábito, mala práctica o mala idea, estos son:
- Algún patrón repetido de acción, proceso o estructura que inicialmente parece ser beneficioso, pero en última instancia produce más malas consecuencias que resultados beneficiosos.
- Una solución refactorizada que está claramente documentada, probada en la práctica real y repetible.
Los nombres que les pusieron tienen un carácter cómico y no son en absoluto oficiales pero su contenido dice mucho. Algunos de los anti-patrones que más se utilizan a la hora de realizar pruebas unitarias son:
- Línea bateador: En la primera mirada, las pruebas cubren todo y las herramientas de cobertura de código lo confirman con un 100%, pero en realidad las pruebas solo afectan al código sin ningún análisis de salida.
- The Free Ride / Piggyback: Aquí en lugar de escribir un nuevo método de caso de prueba para probar otra característica/funcionalidad distinta, una nueva declaración (y sus acciones correspondientes, es decir, pasos de Acta de AAA) se avanza en un caso de prueba ya existente.
- El héroe local: Nos encontramos con un caso de prueba que depende de algo específico del entorno de desarrollo en el que se escribió para poder ejecutarse. El resultado es que la prueba pasa en los cuadros de desarrollo, pero falla cuando alguien intenta ejecutarla en otro lugar.
- La dependencia oculta: En ocasiones se tiene una prueba unitaria que requiere que algunos datos existentes se hayan completado antes de que se ejecute la prueba. Si los datos no se completaron, la prueba fallará y dejará poca indicación al desarrollador de lo que quería, forzándolos a explorar a través del código para descubrir dónde se suponía que provenían los datos que estaba utilizando.
- El inspector: Se trata de una prueba unitaria que infringe la encapsulación en un esfuerzo por lograr una cobertura de código del 100%, pero sabe tanto sobre lo que está sucediendo en el objeto que cualquier bash (intérprete de órdenes) de refactorización romperá la prueba existente y requerirá que cualquier cambio se refleje en la prueba de la unidad.
- Configuración excesiva: Este anti-patrón trata de una prueba que requiere una gran configuración para incluso comenzar a probar. En ocasiones, se usan varios cientos de líneas de código para preparar el entorno para una prueba, con varios objetos involucrados, lo que puede dificultar realmente determinar qué se prueba debido al “ruido” de toda la configuración.
- Sonda anal: Es un anti-patrón donde una prueba tiene que usar formas locas o ilegales para realizar su tarea como leer campos privados usando setAccessible de Java (verdadero) o extender una clase para acceder a campos / métodos protegidos
o tener que poner la prueba en un determinado paquete para acceder paquete de campos / métodos globales. Si ve este patrón, las clases bajo prueba usan demasiada información escondida, piense en una clase que solo tiene campos privados, un método
run()sin argumentos y sin getters. No hay forma de probar esto sin romper las reglas.
- El lento Poke: Es una prueba unitaria que corre increíblemente lenta. Cuando los desarrolladores lo ponen en marcha, tienen tiempo para ir al baño, fumar o, lo que es peor, suspender el examen antes de irse a casa al final del día.
- La prueba parpadeante: Se trata de una prueba que ocasionalmente falla, no en momentos específicos, y generalmente se debe a condiciones de carrera dentro de la prueba. Suele ocurrir al probar algo que es asincrónico.
- Espera y verás: Nos habla de una prueba que ejecuta algún código de configuración y luego necesita ‘esperar’ una cantidad específica de tiempo antes de que pueda ‘ver’ si el código bajo prueba funcionó como se esperaba. Normalmente, puede ver esto si la prueba está probando el código que genera un evento externo al sistema, como un correo electrónico, una solicitud HTTP o escribe un archivo en el disco.
- El gigante: Es una prueba de unidad que, aunque está probando válidamente el objeto bajo prueba, puede abarcar miles de líneas y contener muchos casos de prueba. Esto puede ser un indicador de que el sistema bajo prueba es un Objeto de Dios. Una señal segura para esto es una prueba que abarca más de unas pocas líneas de código. A menudo, la prueba es tan complicada que comienza a contener errores propios.
- Lo creeré cuando vea algunas GUI parpadeantes: El hecho de probar las reglas de negocio a través de la GUI es una forma terrible de acoplamiento. Si escribe miles de pruebas a través de la GUI y luego cambia su GUI, se rompen miles de pruebas. Más bien, pruebe solo elementos de la GUI a través de la GUI, y acople la GUI a un sistema ficticio en lugar del sistema real, cuando ejecuta esas pruebas. Pruebe reglas comerciales a través de una API que no involucra la GUI.
- El guardián secreto: Es una prueba que a primera vista parece no hacer ninguna prueba, debido a la ausencia de aserciones. Pero la prueba realmente se basa en una excepción que se lanzará y espera que el marco de prueba capture la excepción y la informe al usuario como una falla.
- La prueba Forty Foot Pole: Temerosos de acercarse demasiado a la clase que intentan probar, estas pruebas actúan a distancia, separadas por incontables capas de abstracción y miles de líneas de la lógica que están comprobando. Como tales, son extremadamente frágiles y susceptibles a todo tipo de efectos secundarios que ocurren en el viaje épico hacia y desde la clase de interés.
- Doppelgänger: Para probar algo, debe copiar partes del código bajo prueba en una nueva clase con el mismo nombre y paquete y debe usar classpath magic o un cargador de clases personalizado para asegurarse de que sea visible primero (para que su copia sea seleccionada).
Última modificación: miércoles, 16 de marzo de 2022, 12:55