
Página
Tema 4.4 - Normalización de Columnas
Normalización de Columnas
Así es como se ve el dc_listings Dataframe después de todos los cambios que hicimos:

Habrá observado que mientras las columnas de accommodates, bedrooms, bathroms, beds y minimum_nights oscilan entre 0 y 12 (al menos en las primeras filas), los valores de las columnas de maximun_nights y number_of_reviews abarcan rangos mucho mayores, por ejemplo, la columna de noches máximas tiene valores tan bajos como 4 y tan altos como 1825, en las primeras filas mismas, si utilizamos estas dos columnas como parte de un modelo de k- vecinos más cercanos, estos atributos podrían acabar teniendo un efecto desmesurado en los cálculos de distancia, debido a la amplitud de los valores.
Por ejemplo, dos viviendas podrían ser idénticas en todos los atributos pero ser muy diferentes sólo en la columna de maximun_nights, si uno de los listados tiene un valor de maximun_nights de 1825 y el otro un valor de maximun_nights de 4, debido a la forma en que se calcula la distancia euclidiana, estos listados se considerarían muy alejados debido al gran efecto que tiene el tamaño de los valores en la distancia euclidiana general, para evitar que una sola columna tenga demasiado impacto en la distancia, podemos normalizar todas las columnas para que tengan una media de 0 y una desviación estándar de traducción realizada con la versión gratuita del traductor.
La normalización de los valores de cada columna a la distribución normal estándar (media de 0, desviación estándar de 1) preserva la distribución de los valores de cada columna a la vez que alinea las escalas, para normalizar los valores de una columna a la distribución normal estándar, es necesario:
- Restar a cada valor la media de la columna
- Dividir cada valor por la desviación estándar de la columna
Esta es la fórmula matemática que describe la transformación que debe aplicarse a todos los valores de una columna: 
Donde x es un valor de una columna específica, μ es la media de todos los valores de la columna, y σ es la desviación estándar de todos los valores de la columna, este es el aspecto del código correspondiente, utilizando pandas:
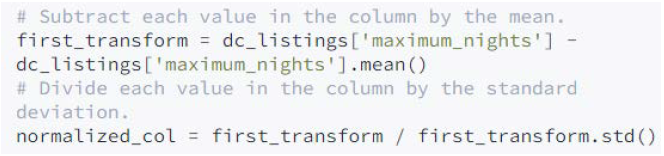
Hay que tener en cuenta que también se puede hacer lo siguiente:

Y se obtiene la misma respuesta que la anterior.
Esto se debe a que first_transform se limita a desplazar la media de la distribución y no tiene ningún efecto sobre la forma o la escala de la distribución, en otras palabras, la varianza de dc_listings es la misma que la varianza de first_transform.
Para aplicar esta transformación a todas las columnas de un Dataframe, puede utilizar los métodos correspondientes de Dataframe mean() y std():

Estos métodos fueron escritos teniendo en cuenta la transformación masiva de las columnas y cuando se llama a mean() o std(), se utilizan las medias y las desviaciones estándar de las columnas apropiadas para cada valor del Dataframe, ahora vamos a normalizar todas las columnas de características en dc_listings.
Instrucciones
- Normalizar todas las columnas de características en dc_listings y asignar el nuevo Dataframe que contiene sólo las columnas de características normalizadas a normalized_listings
- Añadir la columna de price de dc_listings a normalized_listings
- Mostrar las 3 primeras filas de normalized_listings
Soluciones
|
|
|

Última modificación: miércoles, 27 de abril de 2022, 18:17