
Página
Tema 5.3 - Ampliar la Búsqueda en la Cuadrícula
Ampliar la Búsqueda en la Cuadrícula
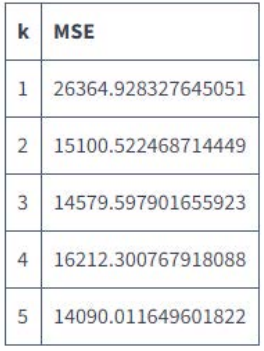
Como nuestro conjunto de datos es pequeño y scikit-learn se ha desarrollado pensando en el rendimiento, el código se ejecutó rápidamente, a medida que aumentamos el valor de k de 1 a 5, el valor de MSE cayó de aproximadamente 26.364 a aproximadamente 14.090:
Vamos a ampliar la búsqueda en la red hasta un valor de k de 20. Aunque 20 puede parecer un punto final arbitrario para nuestra búsqueda en la cuadrícula, siempre podemos ampliar los valores que probamos si no estamos convencidos de que el valor de MSE más bajo está asociado a uno de los valores de hiperparámetro que hemos probado hasta ahora.
Instrucciones
- Cambiar la lista de valores de hiperparámetros, hyper_params, para que vaya de 1 a 20
- Crear una lista vacía y asignarla a mse_values
- Utilice un bucle for para iterar sobre hyper_params y en cada iteración:
- Instancia un objecto KNeighborsRegressor con los siguientes parámetros:
- n_neighbors: el valor actual de la variable del iterador
- algorithm: brute
- Ajustar el modelo k-nearest neighbors instanciado a las siguientes columnas de train_df:
- accommodates
- bedrooms
- bathrooms
- number_of_reviews
- Utilice el modelo entrenado para realizar predicciones sobre las mismas columnas de test_df y asignarlas a las predicciones
- Utilice la función mean_squared_error para calcular el valor MSE entre las predicciones y la columna de precios de test_df
- Añada el valor MSE a mse_values
- Mostrar mse_values con la función print()
Soluciones
|
|
features = ['accommodates', 'bedrooms', "bathrooms" 'number_of_reviews'] hyper_params = [x for x in range(1, 21)] mse_values = List() for hp in hyper_params: knn = KNeighborsRegressor (n_neighbors=hp, algorithm="brute") knn.fit(train_df [features], train_df['price']) predictions = knn.predict(test_df[features]) mse = mean_squared_error(test_df['price'], predictions) mse_values. append (mse) print(mse_values) |

Última modificación: miércoles, 27 de abril de 2022, 23:40