
Página
Tema 2.2 - Computación Distribuida con Hadoop
Objetivos de Aprendizaje
● Entender Hadoop como tecnologías de código abierto para el procesamiento de Big Data
● Comprender el sistema de archivos distribuidos de Hadoop (HDFS)
● Apreciar la arquitectura jerárquica maestro-esclavo de HDFS
● Comprender los dos tipos de archivos de Hadoop: archivos de texto y de secuencia
● Ver código de ejemplo para leer y escribir datos desde HDFS
● Comprender el propósito y el diseño de YARN, el gestor de recursos
Ecosistema / Arquitectura de Big Data

Hadoop y MapReduce Definidos
● Hadoop es un sistema no relacional de almacenamiento de datos distribuido y rentable en hardware básico
● MapReduce es un marco de trabajo para el procesamiento paralelo con un movimiento mínimo de datos y resultados casi en tiempo real
¿Por qué la Computación en Clústeres?
● Arquitectura escalable que utiliza hardware básico
● Cada nodo sirve como servidor de datos y procesamiento
● Cumplir con tres retos:
● Fallo del nodo (MTBF = 3 años)
● Cuello de botella en la red (1Gb / seg)
● Programación distribuida
Arquitectura de Hadoop: Fragmentación de Datos
● Dividir los archivos en trozos (64MB cada uno)
● Almacenar cada trozo en varios nodos

Arquitectura de Maestro – Esclavo (Master-Slave)
● Un nodo es maestro, el resto son esclavos
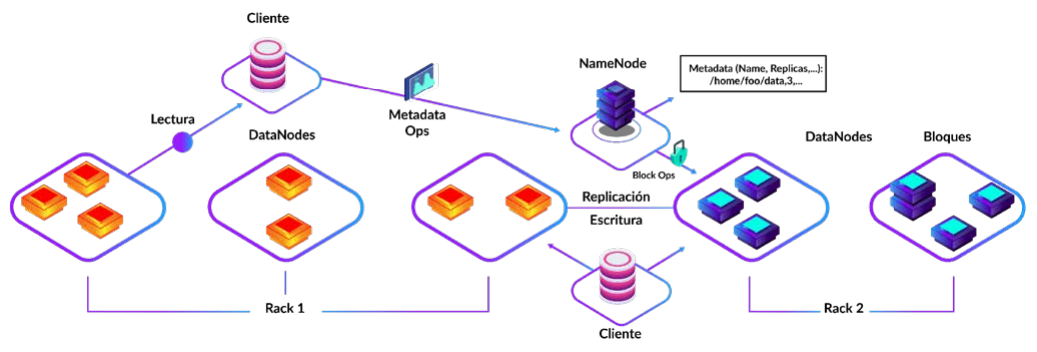
● Hay un NameNode. Este rastrea el contenido de todos los DataNodes
● Cada DataNode contiene trozos de datos

Sistemas de Archivos Distribuidos HDFS
- Namenode: servicio de metadatos
- Datanode: servicio de bloques de datos
Arquitectura de HDFS
Características de HDFS
Ventajas:
Desventajas:
Instalando HDFS
● HDFS tiene un lenguaje shell similar al de Unix
● Los clusters de Hadoop pueden instalarse en:
● Infraestructura en la nube como Amazon Web Services
● Centros de datos propios
● Una sola máquina
● Necesidad de crear al menos dos nodos: Un nodo de nombres y al menos un nodo de datos
Sistemas de Archivos Distribuidos - S3
- Producto de Amazon en el paradigma de AWS
- Plataforma de "almacén de objetos"
- Cubo / llave→ datos
- Sin jerarquía: podemos obtener la lista de claves de un "cubo" (relativamente caro / lento)
- Opción interesante cuando los datos se producen desde AWS (EC2 o EMR)
- Permite hacer públicos los datos muy fácilmente
- Varias Opciones de Autenticación y Autorización
- S3 también es un protocolo: existen otras implementaciones
Ventajas:
- Disponible desde el día 0
- Tiempo de actividad del 99,9%: no está disponible más de 43 minutos al año
- Fácil de usar (HTTP)
Desventajas
- Sistema propietario y opaco
- Potencialmente costoso a largo plazo
- Menos interesante al producir los datos localmente
- Relativamente lento
- Algunas operaciones son contra intuitivamente muy caras (renombrar un archivo es una copia) → requiere especial atención
Sistema de archivos distribuido diseñado y desarrollado por RedHat:
- Conceptualmente similar a HDFS
- Diferencias arquitectónicas fundamentales
- Mds: servicio de metadatos
- Ods: servicio de datos
- My: servicio de supervisión de otros servicios
- Detecta los fallos para mover los datos
- Utiliza un algoritmo de hashing para determinar la ubicación de un bloque Permite una
- Cliente Ceph para hablar directamente con el servicio ods para acceder a los datos
- Sin punto único de fallo (SPOF)
- Admite los 3paradigmas de acceso:
- Tienda de objetos (S3)
- Almacén en bloque (/dev / sda1)
- POSIX (sistema de archivos tradicional)
- Se puede utilizar con Hadoop
- Admite la "codificación de borrado", así como la replicación para evitar la pérdida de datos
- Permite la misma resistencia que la replicación 3x, pero con sólo un 40% de amplificación de
- datos
Sistemas de Archivos Distribuidos CEPH

Ventajas
- Eficiente
- Arquitectura moderna: no hay un solo punto de fallo
- Enorme despliegue de producción (por ejemplo, CERN)
- Versátil: Consolida múltiples casos de uso
Desventajas
Otro Recurso Negociador Más (YARN)>/h3>
● YARN es un sistema operativo distribuido a gran escala para aplicaciones de Big Data
● Gestiona los recursos y supervisa las cargas de trabajo, en un entorno seguro de varios inquilinos, al tiempo que garantiza una alta disponibilidad en varios clústeres de Hadoop
● YARN es una plataforma común para ejecutar múltiples herramientas y aplicaciones, como SQL interactivo (por ejemplo, Hive), streaming en tiempo real (por ejemplo, Spark) y procesamiento por lotes (MapReduce), etc.

Preguntas de Repaso
1. ¿En qué se diferencia Hadoop de un sistema de archivos tradicional?
2. ¿Cuáles son los objetivos de diseño de HDFS?
3. ¿Cómo garantiza HDFS la seguridad e integridad de los datos?
4. ¿En qué se diferencia un nodo maestro del nodo trabajador?
● YARN es un sistema operativo distribuido a gran escala para aplicaciones de Big Data
● Gestiona los recursos y supervisa las cargas de trabajo, en un entorno seguro de varios inquilinos, al tiempo que garantiza una alta disponibilidad en varios clústeres de Hadoop
● YARN es una plataforma común para ejecutar múltiples herramientas y aplicaciones, como SQL interactivo (por ejemplo, Hive), streaming en tiempo real (por ejemplo, Spark) y procesamiento por lotes (MapReduce), etc.
Preguntas de Repaso
1. ¿En qué se diferencia Hadoop de un sistema de archivos tradicional?
2. ¿Cuáles son los objetivos de diseño de HDFS?
3. ¿Cómo garantiza HDFS la seguridad e integridad de los datos?
4. ¿En qué se diferencia un nodo maestro del nodo trabajador?
Última modificación: lunes, 28 de marzo de 2022, 16:45