
Página
Tema 3.1 - Curvas ROC, AUC
Resumen
Las métricas (acurracy, sensivity/specificity, precisión/recall y f-measure) que se obtienen a partir de la matriz de confusión conllevan a que se establezca un punto de corte determinado sobre la distribución de probabilidad para determinar si una observación es clasificada como una clase determinada.
Por ejemplo, aquellos valores por encima de 0,5 se les asigna la clase positiva (1) y aquellos valores iguales o por debajo de 0,5 la clase negativa (0).
En el caso de los algoritmos de clasificación binaria, se puede utilizar una métrica obtenida a partir de las curvas receiver operating characteristic (ROC) conocida como Area under the curve (AUC) o en castellano Área bajo la curva.
La curva ROC nos permite saber qué tan preciso puede distinguir el modelo entre dos cosas, por ejemplo, si un paciente tiene cáncer o no. Los mejores modelos pueden distinguir con precisión entre los dos, mientras que un modelo pobre tendrá dificultades para distinguir entre los dos criterios. (Aprendeia, 2022)
El AUC es el Área bajo la curva. Este puntaje nos da una buena idea de qué tan bien funciona el modelo.
Esta métrica se utiliza para determinar el balance entre la detección de verdaderos positivos y evitar los falsos positivos.

Imagen tomada de:
https://openi.nlm.nih.gov/imgs/512/261/3861891/PMC3861891_CG-14-397_F10.png
A medida que la curva este más cercana de la esquina superior izquierda, mejor será. En el ejemplo, el clasificador de la curva naranja es mejor que el verde, y este mejor que el rojo y el azul. Una clasificación completamente aleatoria coincide con la línea punteada.
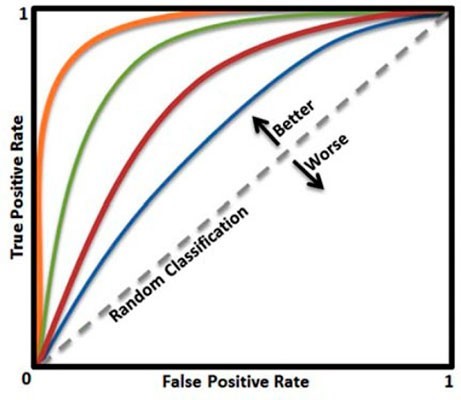
Imagen tomada de:
https://openi.nlm.nih.gov/imgs/512/261/3861891/PMC3861891_CG-14-397_F10.png
A partir de estas curvas se puede obtener el Área bajo la curva (AUC). Esta métrica va desde valores de 0,5 para un clasificador sin potencia predictiva (completamente aleatorio) hasta 1 para un clasificador perfecto. Cuanto más cercanos están los resultados del clasificador perfecto, mejor.
Última modificación: martes, 3 de enero de 2023, 13:45