
Página
Tema 3.1 - SQL Avanzado
Consultas avanzadas - Cláusula With
La cláusula WITH es totalmente opcional y es una cláusula que permite asignar nombres a las subconsultas y puede ser usada en una sola vez o múltiples veces dentro de una misma sentencia. Para poder usar más de una vista dentro de una consulta usando WITH estas serán separadas por comas.
Los resultados devueltos por la cláusula son tablas temporales en memoria similares a las vistas es por esto que a cada una de las consultas definidas en esta se conocen como vistas.
Cabe aclarar que las vistas creadas pueden usarse solo durante de la ejecución de la consulta a la cual pertenecen y estas pueden usarse en toda la consulta las veces que sea necesario siempre y cuando estas ya hayan sido definidas; es decir no pueden usarse en una parte de la consulta anterior a su definición.
El uso la cláusula las que probablemente permitan optimizar las ejecuciones de las consultas. No siempre garantiza la optimización de la consulta, pero lo que si permite es una mejor lectura y mantenimiento de las mismas. También se permite la relación entre las diferentes vistas creadas y por lo tanto crear vistas a partir de vistas anteriores, pero siempre se debe finalizar la sentencia WITH con una consulta a una de las vistas, la cual es la que muestra los resultados requeridos.
Usando una sola vista |
|
Más de una vista |
||||
|---|---|---|---|---|---|---|
|
|
Funciones de analítica
Las funciones analíticas se utilizan para realizar cálculos de valores agregados de un grupo de registros. La diferencia entre las funciones analíticas y las funciones de agregación es que en las primeras se devuelve un conjunto de registros basados en las funciones solicitadas y en la segunda se retorna un único valor basado en el grupo de registros procesado. Las funciones WHERE, GROUP BY y HAVING dentro de una consulta que contenga funciones analíticas se ejecutaran antes de realizar las operaciones analíticas. Y por último si se ejecuta la función ORDER BY.
Cláusula OVER
Esta cláusula es obligatoria en el ámbito de cualquier función analítica. Como palabra clave indica cómo se particiona u ordena la función analítica.
FIRST_VALUE
Esta función permite obtener el primer valor del conjunto ordenado de registros. Se debe tener en cuenta que los valores nulos siempre aparecen de primero, pero se pueden ignorar usando la función IGNORE NULLS.
1 2 3 4 5 6 7 8 9 |
SELECT department_name, manager_id, location_id, FIRST_VALUE(manager_id) IGNORE NULLS OVER ( PARTITION BY location_id ORDER BY location_id ASC ) AS lowest_in_dept FROM departments; |
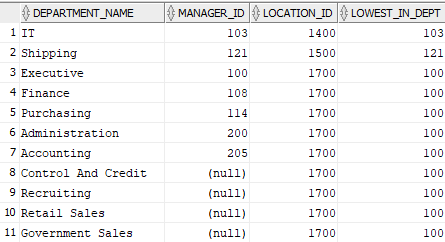
Toma el primer valor del campo MANAGER_ID haciendo la partición de los registros por los diferentes LOCATION_ID y mostrando los resultados ordenador por MANAGER_ID de forma ascendente.
LAST_VALUE
Esta función funciona de la misma manera que FIRST_VALUE pero con el último valor de un conjunto ordenado de valores.
1 2 3 4 |
SELECT department_name,manager_id,location_id,LAST_VALUE(manager_id) IGNORE NULLS OVER (PARTITION BY location_id ORDER BY location_id asc) AS lowest_in_dept FROM departments;NER JOIN vista_2 |

RANK
Como función analítica, calcula el rango de cada fila devuelta de una consulta con respecto a las otras filas retornadas. La siguiente consulta asigna un nivel dando prioridad al campo LOCATION_ID y si estos son iguales toma como segundo parámetro el MANAGER_ID y si tanto LOCATION_ID como MANAGER_ID son iguales se asigna el mismo nivel. Esta prioridad se asigna en el ORDER BY
1 2 3 4 5 6 7 |
SELECT department_name,manager_id,location_id, RANK() OVER ( PARTITION BY location_id ORDER BY location_id ASC, manager_id ASC ) AS RANK FROM departments; |
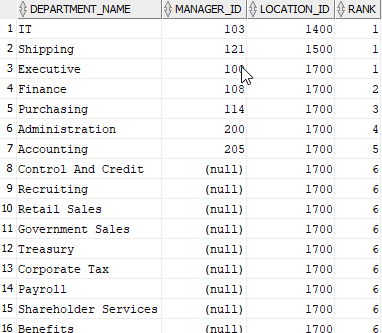
ROW_NUMBER
A diferencia de la función RANK este función analítica asigna un número a cada fila tomando como parámetro principal el valor por el cual se particiona.
1 2 3 4 5 6 7 |
SELECT department_name,manager_id,location_id, ROW_NUMBER() OVER ( PARTITION BY location_id ORDER BY location_id ASC, manager_id ASC ) AS location_order FROM departments; |
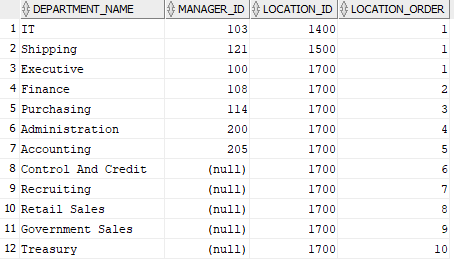
LAG
Esta función analítica retorna registros anteriores a la fila actual, haciendo posible comparar los valores actuales con valores anteriores.
1 2 3 |
SELECT department_name, MANAGER_ID,LOCATION_ID, LAG(MANAGER_ID, 1, 0) OVER(ORDER BY LOCATION_ID, manager_id) AS "Lag value" FROM departments; |
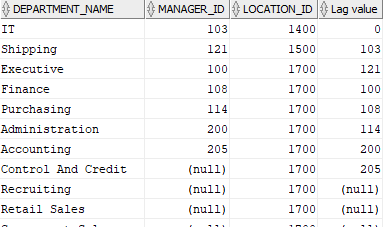
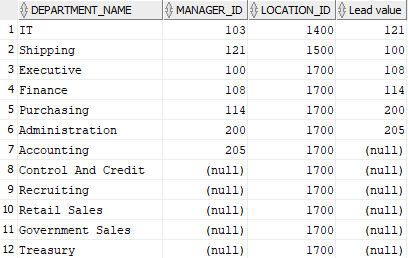
LEAD
La función LEAD hace lo mismo que la función LAG pero trayendo valores posteriores.
1 2 3 |
SELECT DEPARTMENT_NAME, MANAGER_ID,LOCATION_ID, LEAD(MANAGER_ID, 1, 0) OVER(ORDER BY LOCATION_ID, MANAGER_ID) AS "Lead value" FROM DEPARTMENTS; |
Índices
El índice es un instrumento que aumenta la velocidad de respuesta de la consulta, mejorando su rendimiento y optimizando su resultado, pero pueden deteriorar el rendimiento de los INSERT, UPDATE o DELETE. Antes de crear un índice se debe examinar el rendimiento del SQL y comparar el antes y el después.
- ¿Cuándo crear un índice?
- Cuando la columna es frecuentemente usada en las clausulas WHERE.
- Cuando la columna se usa frecuentemente para realizar joins.
- Cuando la columna tenga alta selectividad (Pocas filas tienen el mismo valor).
- Considerar las columnas que forman las claves foráneas para las tablas que tengan alta concurrencia.
- No crear índices sobre columnas que sean actualizadas frecuentemente (Insert, Update, Delete).
- Para índices compuestos considerar las columnas que tengan el operador AND y el orden (primero los filtros únicos).
- Considerar el re-uso de los índices para diferentes consultas.
Optimización
Es el encargado de generar la ruta de acceso necesaria para procesar las consultas SQL. Para cada sentencia SQL existe un numero finito de posibles planes de ejecución. Existen 2 optimizadores:
- Rule Based Optimizer (RBO): Optimizador por defecto para versiones previas a Oracle 9i y obsoleto a partir de la Oracle 10g. Basado en "reglas" y donde el orden de construcción de los querys importa.
- Cost Based Optimizer (CBO): Optimizador por defecto para versiones posteriores a Oracle 9i.
CBO
Selecciona el mejor plan de ejecución; el mejor plan es aquel que utiliza un mínimo de recursos y tiene un tiempo de respuesta menor; para seleccionar este plan se basa en estadísticas. Este se basa en las reglas básicas, pero teniendo en cuenta el estado actual de la base de datos: cantidad de memoria disponible, entradas/salidas, estado de la red. En ocasiones el mejor plan de ejecución puede no ser el plan más optimo y esto puede deberse a:
- Falta de estadísticas.
- Estadísticas parciales o incompletas.
- Desconocimiento de las características de hardware.
- Desconocimiento de la carga actual.
- Parametrización del motor.
- Construcciones incorrectas por parte del optimizador.
¿Qué significa el costo de un SQL?
El costo de un SQL es el costo total del plan de ejecución; por ende, el mejor plan de ejecución será aquel que tenga un menor costo. Los costos de un SQL no pueden ser comparado con el costo de otro SQL y tampoco puede ser comparado con el costo del mismo SQL en otro ambiente diferente. El optimizador es sensible a cambios, tales como Patches y Updates del motor, configuración del servidor donde está la BD, sistema operativo; además puede ser influenciado por hints.
Con el fin de ayudar al optimizador que podemos hacer:
- Mantener actualizadas las estadísticas de los objetos y del sistema.
- Utilizar histogramas.
- Seguir buenas prácticas en la construcción de SQL.
- Revisar y optimizar los planes de ejecución.
- Realizar seguimiento a los planes de ejecución de aquellas sentencias criticas
HINTS
Los hints son pistas que se dan al optimizador SQL de Oracle para que elabore el plan de ejecución de una sentencia DML, sentencias de manipulación de datos como select, insert, update, delete.
SELECT /*+ COMANDO-HINT */ ...
- /*+ CHOOSE */ Pone la consulta a costes.
- /*+ RULE */ Pone la consulta a reglas.
- /*+ ALL_ROWS */ Pone la consulta a costes y la optimiza para que devuelva todas las filas en el menor tiempo posible. Es la opción por defecto del optimizador basado en costes. Esto es apropiado para procesos en masa, en los que son necesarias todas las filas para empezar a trabajar con ellas.
- /*+ FIRST_ROWS */ Pone la consulta a costes y la optimiza para conseguir que devuelva la primera fila en el menor tiempo posible. Esto es idóneo para procesos online, en los que podemos ir trabajando con las primeras filas mientras se recupera el resto de resultados. Este hint se desactivará si se utilizan funciones de grupo como SUM, AVG, etc.
- /*+ INDEX( tabla índice ) */ Fuerza la utilización del índice indicado para la tabla indicada. Se puede indicar el nombre de un índice (se utilizará ese índice), de varios índices (el optimizador elegirá uno entre todos ellos) o de una tabla (se utilizará cualquier índice de la tabla).
- /*+ ORDERED */ Hace que las combinaciones de las tablas se hagan en el mismo orden en que aparecen en el join.
- “No son recomendados a menos que se detecte una inconsistencia en el optimizador.”
Planes de Ejecución
Es la representación de la ruta o pasos que debe seguir el motor para ejecutar un SQL. El explain plan muestra la ruta de ejecución estimada, la cual puede diferir del plan de ejecución real del SQL. El plan de ejecución nos proporciona muchos datos que pueden ser útiles para averiguar qué está ocurriendo al ejecutar una consulta, pero principalmente, de lo que nos informa es del tipo de optimizador utilizado, y el orden y modo de unir las distintas tablas si la instrucción utiliza algún join.
|
Columna |
Descripción |
|
Statement_ID |
Da “nombre” al plan de ejecución para futuras consultas. |
|
Timestamp |
Registro del momento en el que se ejecutó el comando EXPLAIN PLAN. |
|
Remarks |
Una columna “comentario”; puedes añadir comentarios a los registros de PLAN_TABLE mediante el comando UPDATE. |
|
Operation |
La operación SQL realizada en la etapa. |
|
Options |
La opción utilizada para la operación, como puede ser UNIQUE SCAN, RANGE SCAN, … |
|
Object_Node |
EL database link usado para referenciar al objeto. |
|
Object_Owner |
El propietario del objeto referenciado en la operación. |
|
Object_Name |
El nombre del objeto referenciado en la operación. |
|
Object_Instance |
La posición ordinal del objeto en el SQL analizado. |
|
Object_Type |
Un atributo del objeto, como UNIQUE para los índices. |
|
Optimizer |
El modo en que está el optimizador, como CHOOSE, RULE, … |
|
Search_Columns |
No se usa actualmente |
|
ID |
Un número asignado a cada etapa en el EXPLAIN_PLAN. Junto con el Parent_ID establece la jerarquía de etapas en el plan de ejecución. |
|
Parnt_ID |
El ID de la etapa que es el “padre” de la etapa actual en la jerarquía del plan de ejecución. |
|
Position |
El orden de proceso para etapas con el mismo Parent_ID. En la primera línea generada por EXPLAIN PLAN contiene la estimación del coste de la consulta realizado por el optimizador (si está en modo COSTES). |
|
Cost |
Coste relativo de la etapa. |
|
Cardinality |
Cardinalidad de un índice o el número de filas esperado que devuelva la operación. |
|
Bytes |
El tamaño de cada fila devuelta |
|
Other_Tag |
Si el valor es SERIAL_FROM_REMOTE, el SQL en la columna Other se ejecutará en el nodo remoto. Otros valores describen el uso de la operación en Parallel Query Option |
|
Other |
Para consultas distribuidas, Other contiene el texto del SQL que es ejecutado en el nodo remoto. |
Operaciones de fila o grupo
|
Fila |
Grupo |
|
Ejecuta una fila cada vez |
Ejecuta el resultado de un grupo de filas |
|
Se ejecuta en la fase de FETCH, si no hay operaciones de grupo implicadas. |
Se ejecuta en la fase de EXECUTE cuando el cursor está abierto. |
|
El usuario ve el primer resultado antes de que se recupere la última fila. |
El usuario no ve el resultado hasta que no se han procesado todas las filas. |
Operaciones SQL
|
Operación |
Tipo |
Uso |
|
AND-EQUAL |
Fila |
Operación AND entre dos o más columnas con un single column nonunique index. |
|
CONCATENATION |
Fila |
Operación OR o IN (lista de valores) |
|
CONNECT BY |
Fila/Grupo |
Operación CONNECT BY |
|
COUNT |
Grupo |
Operación SELCT ROWNUM |
|
COUNT STOPKEY |
Fila |
Operación ROWNUM <= constante |
|
FILTER |
Fila |
Condición para filas devueltas por operaciones de grupo (como HAVING) |
|
FOR UPDATE |
Fila |
cláusula FOR UPDATE |
|
HASH JOIN |
Grupo |
Se utiliza un HASH JOIN en el cruce de las tablas |
|
INDEX FULL SCAN |
Fila |
ORDER BY en un single column index |
|
INDEX RANGE SCAN |
Fila |
BETWEEn, LIKE, >, <, >=, <=. Se está utilizando un índice no-único o las primeras columnas de un índice compuesto. |
|
INDEX UNIQUE SCAN |
Fila |
Uso de un índice único |
|
INTERSECTION |
Grupo |
Operación INTERSECTION |
|
MERGE JOIN |
Fila |
Se utiliza un MERGE JOIN en el cruce de las tablas |
|
MINUS |
Grupo |
Operación MINUS |
|
NESTED LOOP |
Fila |
Se utiliza un NESTED LOOPS JOIN en el cruce de las tablas |
|
OUTER JOIN |
Fila |
Un NESTED LOOPS JOIN cuando se utiliza la expresión OUTER JOIN (+) |
|
PROJECTION |
Fila |
El resultado de las operaciones UNION, MINUS e INTERSECTION |
|
REMOTE |
Fila/Grupo |
Una operación en la que está presente un DATABASE LINK |
|
SEQUENCE |
Fila |
Operación secuencia.NEXTVAL |
|
SORT AGGREGATE |
Grupo |
Uso de la función de grupo SUM() |
|
SORT GROUP BY |
Grupo |
Uso de la cláusula GROUP BY |
|
SORT JOIN |
Grupo |
El resultado de un MERGE JOIN |
|
SORT ORDER BY |
Grupo |
Uso de la cláusula ORDER BY |
|
SORT UNIQUE |
Grupo |
Uso de la cláusula DISTINCT o el resultado de la operación UNION |
|
TABLE ACCESS BY ROWID |
Fila |
Acceso a la tabla vía un índice o con un ROWID determinado |
|
TABLE ACCESS CLUSTER |
Fila |
Acceso a una tabla de un cluster usando la clave del cluster |
|
TABLE ACCESS FULL |
Fila |
Acceso a la tabla cuando ninguna condición se aplica a columnas indexadas |
|
TABLA ACCESS HASH |
Fila |
Acceso a un HASH CLUSTER utilizando la HASH KEY |
|
UNION |
Fila |
Operación UNION (elimina duplicados) |
|
UNION-ALL |
Fila |
Operación UNION-ALL (no elimina duplicados) |
|
VIEW |
Grupo |
Uso de una subconsulta o cuando se fuerza la ejecución de una vista antes de que se pueda resolver la consulta. |
Última modificación: miércoles, 20 de mayo de 2020, 23:33