
Página
Tema 4.7 - Ajuste de un Modelo y Realización de Predicciones
Ajuste de un Modelo y Realización de Predicciones
Ahora, podemos ajustar el modelo a los datos utilizando el método de ajuste (fit_method), para todos los modelos, el método de ajuste (fit) toma 2 parámetros necesarios:
- Objeto tipo matriz, que contiene las columnas de características que queremos utilizar del conjunto de entrenamiento
- Objeto tipo lista, que contiene los valores objetivo correctos
El objeto tipo matriz significa que el método es flexible en la entrada y se acepta un Dataframe o un array de valores NumPy 2D, esto significa que puedes seleccionar las columnas que quieres utilizar de Dataframe y utilizarlo como primer parámetro del método de ajuste (fit) Si recuerdas que anteriormente en la misión, todos los siguientes son objetos tipo lista aceptables:
- Matriz NumPy
- Lista de Python
- Objeto Pandas Series (por ejemplo, al seleccionar una columna)
Puede seleccionar la columna objetivo del marco de datos y utilizarla como segundo parámetro del método de ajuste (fit):
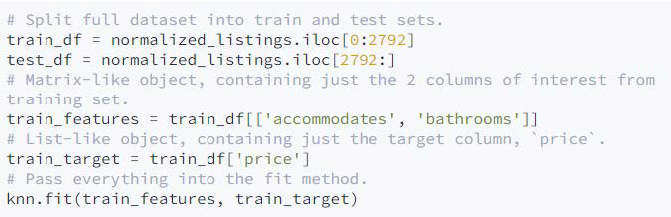
Cuando se llama al método fit(), scikit-learn almacena los datos de entrenamiento que especificamos dentro de la instancia KNearestNeighbors (knn), si intenta pasar datos que contengan valores perdidos o valores no numéricos en el método fit, scikit-learn devolverá un error, scikit-learn contiene muchas características de este tipo que nos ayudan a prevenir errores comunes.
Ahora que hemos especificado los datos de entrenamiento que queremos usar para hacer predicciones, podemos usar el método predecir (predict method) para hacer predicciones en el conjunto de prueba, el método predict sólo tiene un parámetro requerido:
- Un objeto tipo matriz, que contiene las columnas de características del conjunto de datos sobre el que queremos hacer predicciones
El número de columnas de características que se utiliza durante el entrenamiento y la prueba tiene que coincidir o scikit-learn devolverá un error:

El método predict() devuelve un array NumPy que contiene los valores de precio predichos para el conjunto de prueba, ahora tienes todo lo que necesitas para practicar todo el flujo de trabajo de scikit learn.
Instrucciones
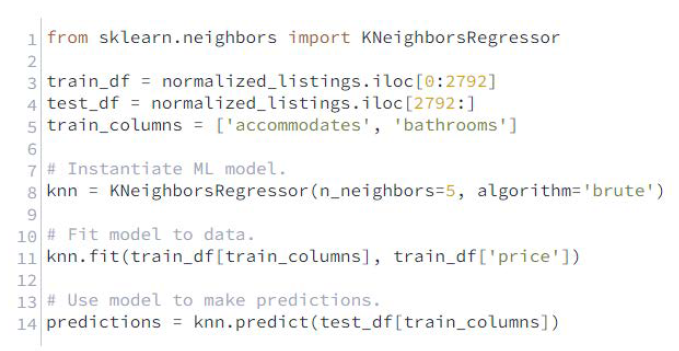
- Cree una instancia de la clase KNeighborsRegressor con los siguientes parámetros:
- n_neighbors: 5
- Utiliza el método fit para especificar los datos que queremos que utilice el modelo k-nearest neighbor. Utiliza los siguientes parámetros:
- Datos de entrenamiento, columnas de características: sólo las columnas de accommodates y bathrooms, en ese orden, de train_df
- Datos de entrenamiento, columna objetivo: la columna de precios de train_df
- Llame al método predict para hacer predicciones sobre:
- Las columnas de accommodates y bathrooms de test_df
- Asignar la matriz NumPy resultante de los valores de precio predichos a las predicciones (predictions)
Soluciones
|
|
|
Última modificación: miércoles, 27 de abril de 2022, 23:10