
Página
Tema 3.3 - Algoritmos de Big Data
Introducción a los Algoritmos
● Estadística descriptiva
● Inferencia estadística
● Correlación
● Regresión
● Clasificación
● Agrupación
● Detección de valores atípicos
● Visualización de datos
● Los algoritmos pueden realizar tareas de cálculo, procesamiento de datos y razonamiento automatizado
● Aplicando algoritmos a grandes volúmenes de datos, se pueden obtener valiosos conocimientos y percepciones
● La aplicación de algoritmos, y su posterior uso para Big Data, se basa en el dominio científico de la estadística
● Por lo tanto, todas las personas involucradas en la ciencia de los datos deberían tener un conocimiento fundamental sobre las operaciones estadísticas y cómo podrían aplicarse en los algoritmos
Ejemplo de un Algoritmo Simple

Figura 22: Ejemplo de algoritmo sencillo para encontrar el valor máximo en un conjunto de datos
Estadísticas Descriptivas
● Las estadísticas descriptivas son estadísticas de resumen que describen o resumen cuantitativamente las características de una colección de información
● A continuación se explican las estadísticas descriptivas:
- Estadísticas de tendencia central
- Estadísticas de dispersión
- Formas de distribución
● Las estadísticas de tendencia central (o medidas de tendencia central) son típicas para definir valores en conjuntos de datos
● Estos estadísticas describen cómo se organizan varios puntos de datos en torno a su punto central ● Las medidas de tendencia central más comunes son:
1. Media
2. La mediana
3. Moda
Media: La media aritmética (o simplemente "media") de una muestra es la suma de los valores muestreados dividida por el número de elementos de la muestra. En el siguiente ejemplo, la media se calcula para un grupo de jugadores de baloncesto.

Figura 23: El calculo de la media
Mediana: La mediana es el valor que separa la mitad superior de una muestra de datos, una población o una distribución de probabilidad, de la mitad inferior, para un conjunto de datos, puede considerarse como el valor "medio", en el siguiente ejemplo, se calcula la mediana para otro grupo de jugadores de baloncesto.

Figura 24: El cálculo de la mediana.
Moda: La moda de un conjunto de valores de datos es el valor que aparece con más frecuencia, en otras palabras, es el valor que tiene más probabilidades de ser muestreado.

Figura 25 : El calculo de la moda
Estadísticas de Dispersión
● En estadística, la dispersión (también llamada variabilidad o dispersión) es el grado de estiramiento o compresión de una distribución, las estadísticas de dispersión indican cómo se distribuyen los puntos de datos alrededor de sus valores centrales.
● Las medidas de dispersión estadística son:
1. Rango
2. Rango intercuartil
3. Varianza
4. Desviación estándar
Tipos Estadísticas de Dispersión
Rango: El rango de un conjunto de datos es la diferencia entre el mayor y el menor valor.

Figura 26: El cálculo del Rango
Rango Intercuartílico
● El rango intercuartílico (IQR), también llamado dispersión media o 50% medio, es una medida de dispersión que equivale a la diferencia entre los percentiles 75 y 25 (QR = Q3 - Q1)
● En otras palabras, el IQR es una estadística que indica dónde se encuentra el 50% medio de los valores, según el ejemplo siguiente:

Figura 27: El cálculo del rango intercuartílico
Varianza
● La varianza es la expectativa de la desviación al cuadrado de una variable aleatoria respecto a su media. De manera informal, mide la dispersión de un conjunto de números (aleatorios) con respecto a su valor medio
● Cuanto más se acerque la varianza a cero, más agrupados estarán los puntos de datos
● La varianza de un conjunto de datos se calcula siguiendo estos pasos:
- Reste la media de cada valor de los datos. Así se obtiene una medida de la distancia de cada valor a la media
- Eleve al cuadrado cada una de estas distancias (para que todas sean valores positivos) y sume todos los cuadrados
- Divida la suma de los cuadrados por el número de valores del conjunto de datos
El Cálculo de la Varianza

Figura 28: El Cálculo de la Varianza
Desviación Estándar:
● La desviación estándar (SD, también representada por la letra griega sigma σ o la letra latina s) es una medida que se utiliza para cuantificar la cantidad de variación o dispersión de un conjunto de valores de datos
● Una desviación estándar baja indica que los puntos de datos tienden a estar cerca de la media (también llamada valor esperado) del conjunto, mientras que una desviación estándar alta indica que los puntos de datos están dispersos en un rango más amplio de valores
● La forma de calcular la desviación estándar es exactamente la misma que la de la varianza, con la diferencia de tomar la raíz cuadrada de la varianza
Comparación de una Desviación Estándar Baja y Alta

Figura 29: Comparación de una desviación estándar baja y desviación estándar alta
Formas de Distribución
● Una distribución es un grupo de números o una función que muestra todas las ocurrencias de los diferentes valores o resultados de una variable. En otras palabras, muestra cómo se distribuyen los valores de una variable
● En el análisis y la analítica de Big Data, se utilizan varias distribuciones comunes:
- Distribución de frecuencias
- Distribución de probabilidad
- Distribución de muestreo
- Distribución normal
Distribución de frecuencias
● Una distribución de frecuencias es una tabla o un gráfico que muestra la frecuencia de varios resultados en una muestra
● Cada entrada de la tabla contiene la frecuencia o el recuento de las ocurrencias de los valores dentro de un grupo o intervalo concreto, y de esta manera, la tabla resume la distribución de los valores en la muestra.(Figura: Distribución de frecuencias de los jugadores de baloncesto)
Distribución de probabilidades
● Una probabilidad es la "posibilidad" o probabilidad de que se produzca un determinado resultado. La probabilidad de que una moneda flip salga cruz es de 0,5, lo que indica que hay un 50% de que la moneda salga cruz en un futuro flip. (Figura: Ejemplo de distribución de probabilidad)
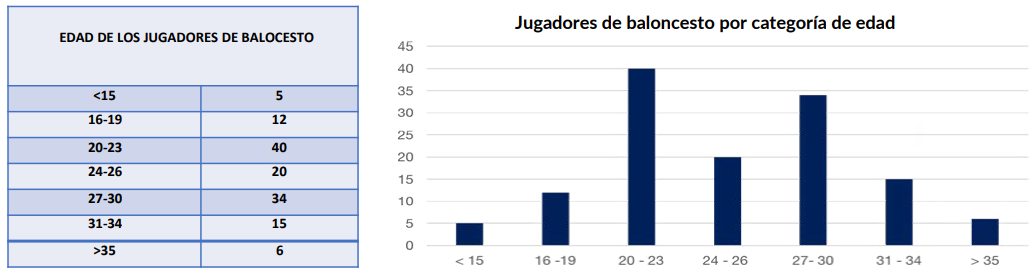
Figura 30: Distribución de Frecuencias de los Jugadores de Baloncesto.
Ejemplo de Distribución de la Probabilidad
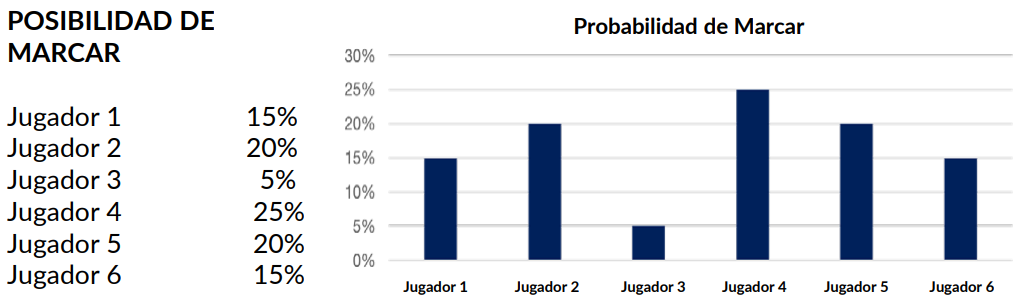
Figura 31: Ejemplo de Distribución de la Probabilidad
Distribución muestral
● Una distribución de muestreo es la distribución de probabilidad de una estadística determinada basada en una muestra aleatoria
● Las distribuciones de muestreo son importantes en Big Data porque proporcionan una importante simplificación que puede utilizarse para el análisis predictivo
Distribución normal
● La distribución normal (o más conocida como gaussiana) es la distribución de probabilidad continua más importante y común
● Las distribuciones normales son importantes en estadística y se utilizan a menudo en la ciencia de los datos para representar variables aleatorias de valor real cuyas distribuciones no se conocen
● Una distribución normal tiene la misma media, mediana y moda
Distribución Normal
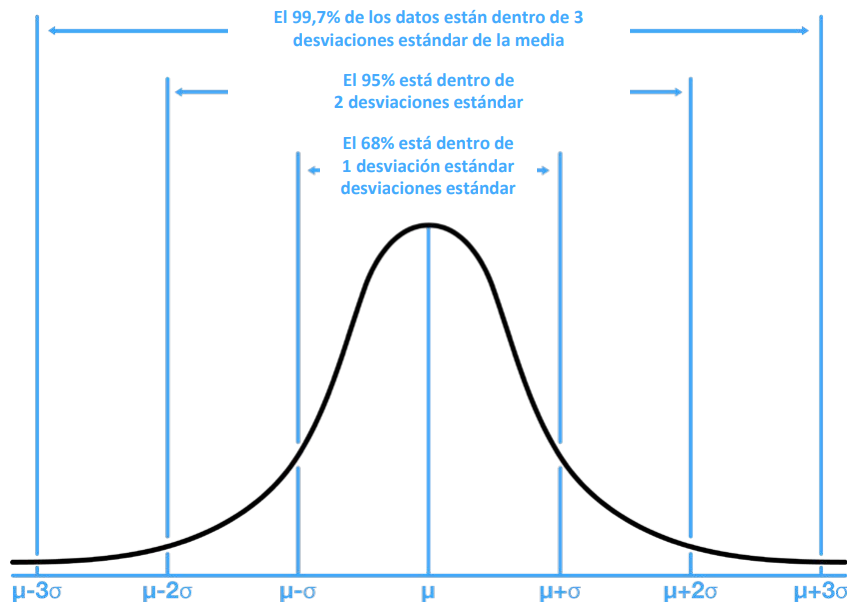
Figura 32: Forma y propiedades de la distribución normal
Asimetría Estadística
La asimetría es una medida de la asimetría de una distribución de probabilidad de una variable aleatoria de valor real en torno a su media. El valor de la asimetría puede ser positivo o negativo, o no definido.
● Asimetría negativa: Una distribución está sesgada negativamente cuando la cola de la curva es más larga en el lado izquierdo o está sesgada hacia la izquierda, y la media es menor que la mediana y la moda. La mayoría de los valores se encuentran en el lado derecho de la curva
● Sesgo positivo: Una distribución está sesgada positivamente cuando la cola de la curva es más larga en el lado derecho o está sesgada hacia la derecha, y la media es mayor que la mediana y la moda. La mayoría de los valores se encuentran en el lado izquierdo de la curva
Distribuciones Asimétricas Positivas y Negativas
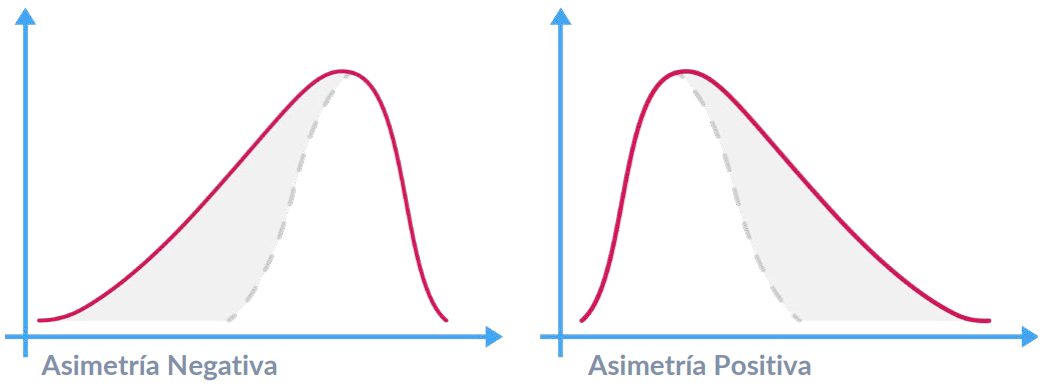
Figura 33: Distribuciones Asimétricas Positivas y Negativas
Inferencia Estadística
● La inferencia estadística es el proceso de deducir propiedades de una muestra de datos (es decir, una distribución de probabilidad) para hacer predicciones sobre todo el grupo de datos
● La estadística inferencial deduce que si se pueden probar ciertas características de una muestra, es probable que estas características también estén presentes en toda la población
- Poblaciones y muestras
- Sesgo
- Poblaciones, muestras y sesgos en Big Data
Poblaciones y Muestras
● Una población es un conjunto de elementos o eventos similares que son de interés para algún experimento
● Es todo el grupo el que interesa al experimento
● Sin embargo, desde la perspectiva de la recopilación de datos, con frecuencia no es posible contar con toda la población
● Una muestra es un subconjunto de la población que se está analizando y sobre la que hay datos disponibles
● Los elementos de una muestra se conocen como puntos de muestra, unidades de muestreo u observaciones
● Los análisis estadísticos y los algoritmos se aplican a los datos de la muestra para hacer suposiciones y declaraciones sobre toda la población
Sesgo
● Si la muestra que se ha seleccionado no es una representación adecuada de toda la población, se denomina muestra sesgada
● El sesgo dará lugar a predicciones inadecuadas o erróneas sobre el futuro, porque en la estadística inferencial se hacen suposiciones sobre toda la población basadas en la muestra
● La mayoría de las predicciones incorrectas en estadística se hacen cuando los datos de la muestra están sesgados
Poblaciones, Muestras y Sesgos en Big Data
● El sesgo puede dar lugar a predicciones inadecuadas porque la muestra no siempre representa a la población
● La única forma de eliminar completamente el sesgo es cuando la muestra es igual a la población real
● Con el Big Data, es posible analizar cantidades masivas de datos. Cuanto mayor sea el conjunto de datos, más se acercará a la población real y menos probable será que el conjunto de datos esté sesgado
● En otras palabras, gracias al Big Data, las predicciones sobre el futuro son cada vez más precisas
Correlación
● La dependencia (o asociación) es cualquier relación estadística, causal o no, entre dos variables aleatorias o datos bivariantes
● En la correlación, dos (o más) variables se comparan entre sí. Estas variables pueden ser dependientes o independientes:
- Las variables independientes no se ven modificadas o afectadas por los cambios en la otra variable. Funcionan de forma independiente y con frecuencia se modifican para comprobar el efecto sobre la variable dependiente
Ejemplos comunes de variables independientes son la temperatura, la edad o la altura de los jugadores de baloncesto
2. Las variables dependientes son las que cambian en función de las fluctuaciones de la variable
independiente. Las variables dependientes representan el producto o resultado cuya variación
se está estudiando
Ejemplo anterior, la probabilidad de ser seleccionado para las pruebas de la NBA es la variable dependiente que nos gustaría conocer (dependiente de la variable independiente de ʻla altura de los jugadoresʼ)
● El coeficiente de correlación de Pearson es la medida de una correlación linear entre dos variables X y Y
● Tiene un valor entre +1 y -1, donde 1 es la correlación lineal positiva total, 0 es no correlación lineal, y -1 es correlación lineal negativa total
● Es ampliamente usada en ciencia de datos para detectar relaciones entre variables
● Correlaciones que están cerca a -1 o +1 son consideradas correlaciones fuertes, porque las variables tienden a moverse en direcciones similares
Ejemplos de Coeficientes de Correlación de Pearson

Figura 34: Ejemplos de Coeficientes de Correlación de Pearson
Regresión
● El análisis de regresión es un conjunto de procesos estadísticos para estimar las relaciones entre variables
● Incluye muchas técnicas de modelización y análisis de varias variables, cuando la atención se centra en la relación entre una variable dependiente y una o más variables independientes (o "predictores")
● En la regresión, tratamos de encontrar la mejor línea de ajuste para hacer predicciones (o pronósticos) sobre la relación entre las variables. Debido a su naturaleza predictiva, se utiliza ampliamente en el aprendizaje automático para encontrar relaciones en conjuntos de datos
Regresión Lineal Simple
● Encontrar una relación lineal entre la variable dependiente y la variable independiente x a partir de la siguiente función de regresión simple: y = α x + β
● Donde α es la pendiente de la línea de mejor ajuste y β es igual a la intersección de y
● El objetivo es fincar los valores de y β que proporcionen el mejor " ajuste" a través de todos los puntos de datos disponibles
Línea de Mejor Ajuste
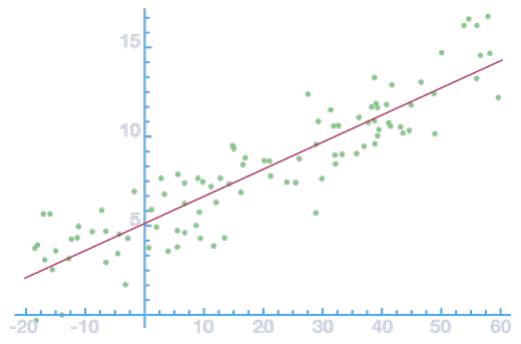
Figura 35: La regresión lineal tiene como objetivo encontrar la línea de mejor ajuste
Similitudes y Diferencias entre Correlación y Regresión
● La correlación sólo indica si existe una relación, mientras que la regresión pretende estimar el alcance de esta relación con fines predictivos
● En primer lugar, algunas similitudes importantes entre la correlación y la regresión:
- El coeficiente de regresión estandarizado es el mismo que el coefficiente de correlación de Pearson
- El cuadrado del coeficiente de correlación de Pearson es el mismo que el R2 de la regresión lineal simple
- Ni la regresión lineal simple ni la correlación responden directamente a cuestiones de causalidad
● En segundo lugar, algunas diferencias importantes entre correlación y regresión:
- Aunque la correlación se refiere típicamente a la relación lineal, puede referirse a otras formas de dependencia, como las relaciones polinómicas o verdaderamente no lineales
- Mientras que la correlación se refiere típicamente al coeficiente de correlación de Pearson, hay otros tipos de correlación, como la de Spearman
Clasificación
● La clasificación es el problema de identificar a cuál de un conjunto de categorías pertenece una nueva observación, basándose en un conjunto de datos de entrenamiento que contiene observaciones cuya pertenencia a una categoría es conocida. Dado que el ordenador recibe datos de muestra, la clasificación es una forma de aprendizaje automático supervisado
● Un algoritmo de clasificación ̶ simplificado ̶ ejecuta los siguientes pasos:
- Un ordenador recibe datos de muestra que contienen información sobre la clase de cada punto de datos. Por ejemplo, aprende a clasificar las zanahorias como "verduras" y las naranjas como "frutas"
- Tras el "entrenamiento" de la máquina, se proporcionan nuevos datos u observaciones al ordenador
- Ahora el ordenador empieza a clasificar por sí mismo. En el ejemplo, los comestibles que tienen características similares a las zanahorias serán etiquetados como "verduras", mientras que los comestibles que tienen características similares a las naranjas serán etiquetados como "frutas"
Ejemplo de Clasificador Lineal

Figura 36: Un ejemplo de clasificador lineal
Clustering
● El análisis de clústeres o clustering es la tarea de agrupar un conjunto de objetos de tal manera que los objetos del mismo grupo (llamado clúster) sean más similares (en algún sentido) entre sí que los de otros grupos (clústeres)
● La agrupación es un ejemplo de aprendizaje no supervisado
● No hay datos de muestra que se "introduzcan" primero en la máquina, sino que el ordenador empieza a formular clústeres basados en las similitudes entre los grupos
● Para llegar a un clúster, el ordenador tiene que ejecutar un algoritmo de agrupación
● Existen muchos algoritmos de clustering conocidos, dependiendo de las características del problema a resolver. Un aspecto común es que la mayoría de los algoritmos de clustering se fijan en la "similitud" entre los puntos de datos
Un Ejemplo de Agrupación - Aprendizaje Automatizado no Supervisado
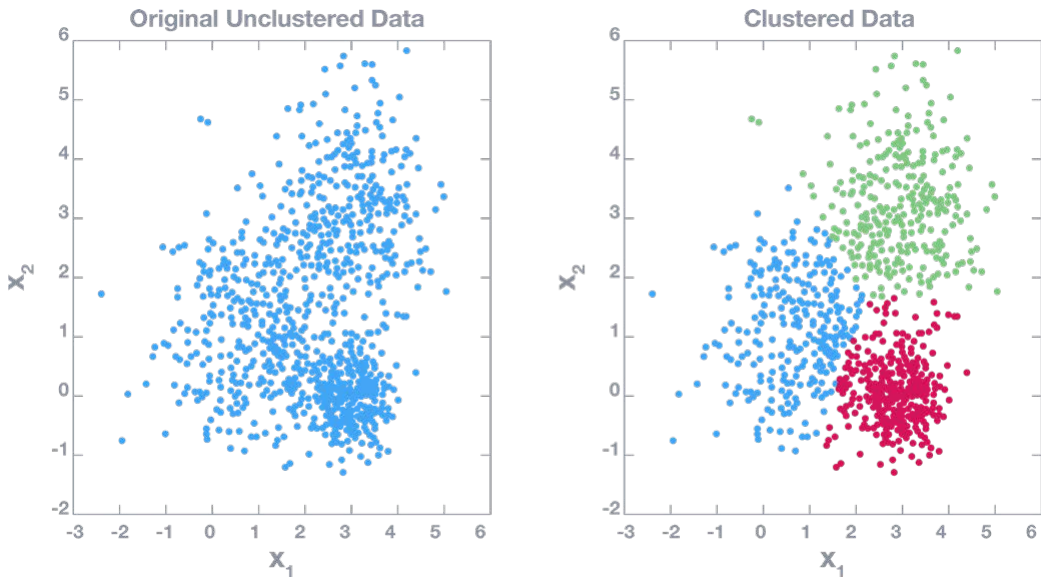
Figura 37: Un ejemplo de agrupación - Aprendizaje Automatizado no Supervisado
Detección de Anomalías
● Un valor atípico es un punto de observación que se aleja de otras observaciones
● Un valor atípico puede deberse a la variabilidad de la medición o puede indicar un error en los datos
● Especialmente en el análisis de conjuntos de Big Data, la detección de valores atípicos es una técnica frecuentemente utilizada para detectar puntos de datos erróneos o falsos
● La distribución normal estándar puede utilizarse para detectar valores atípicos
● Recordemos que, dentro de la distribución normal, el 99% de los puntos de datos se sitúan dentro de las tres desviaciones estándar de la media
● Por lo tanto, si uno o más puntos de datos se alejan más de tres desviaciones estándar de la media, esto podría ser una indicación de que estos puntos son incorrectos o contienen datos defectuosos. (Figura: Detección de valores atípicos mediante la distribución normal estándar
Detección de Valores Atípicos para Detectar Puntos de Datos Erróneos

Figura 38: Detección de valores atípicos para detectar puntos de datos erróneos
Detección de Valores Atípicos a Través de la Distribución Normal Estándar
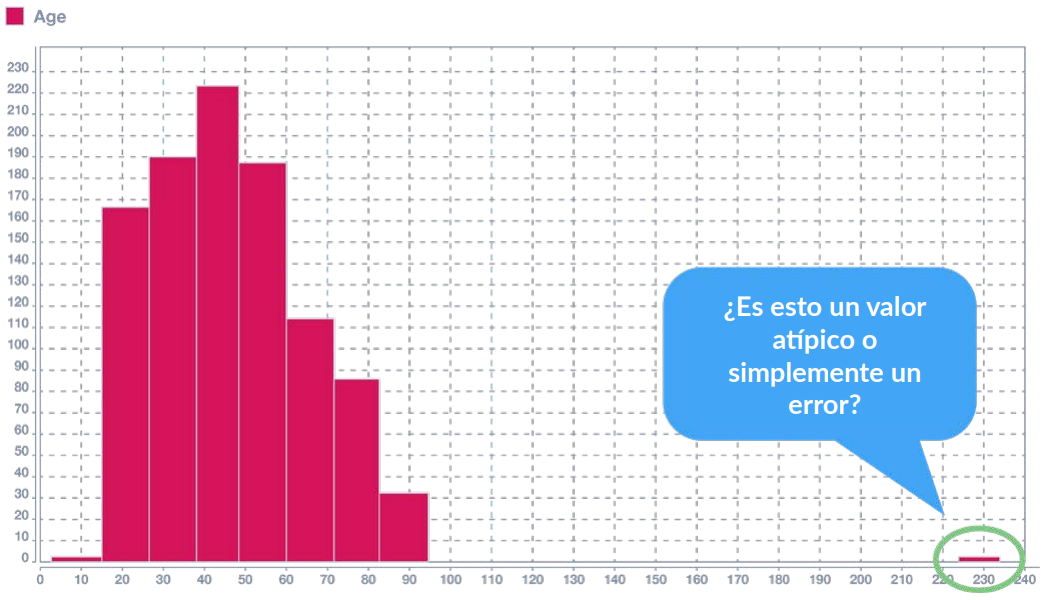
Figura 39: Detección de valores atípicos mediante la distribución normalizada
Visualización de Datos
● La visualización de datos se utiliza ampliamente en el ámbito del Big Data, porque condensa grandes conjuntos de datos en gráficos de resumen que son fáciles de entender y de discutir
● Las técnicas de visualización de datos más comunes y sus propiedades:
- Gráficos de barras
- Histogramas
- Gráficos de dispersión
- Diagramas dobles
- Gráficos de caja
- Gráficos Q-Q
- Gráficos de tarta
- Gráficos de radar
Tipos de Técnicas de Visualización de Datos
Gráficos de barras:● Un diagrama de barras o gráfico de barras es un diagrama o gráfico que presenta datos categóricos
con barras rectangulares con alturas o longitudes proporcionales a los valores que representan
● Las barras pueden representarse vertical u horizontalmente. Un gráfico de barras vertical se denomina a veces gráfico de líneas (Figura: Ejemplo de gráfico de barras)
● Las barras pueden representarse vertical u horizontalmente. Un gráfico de barras vertical se denomina a veces gráfico de líneas (Figura: Ejemplo de gráfico de barras)
Histogramas:
● Un histograma es una representación precisa de la distribución de datos numéricos
● Es una estimación de la distribución de probabilidad de una variable continua (variable cuantitativa)
● Un histograma es similar a un gráfico de barras, pero cada una de las barras está conectada a la otra (Figura: Ejemplo de un histograma)
● Es una estimación de la distribución de probabilidad de una variable continua (variable cuantitativa)
● Un histograma es similar a un gráfico de barras, pero cada una de las barras está conectada a la otra (Figura: Ejemplo de un histograma)
Gráficos de dispersión:
● Un gráfico de dispersión es un tipo de gráfico o diagrama matemático que utiliza coordenadas
cartesianas para mostrar los valores de dos variables típicas de un conjunto de datos. Si los puntos
están codificados por colores, se puede mostrar una variable adicional (Figura: Ejemplo de gráfico
de dispersión)
Ejemplo de Histograma
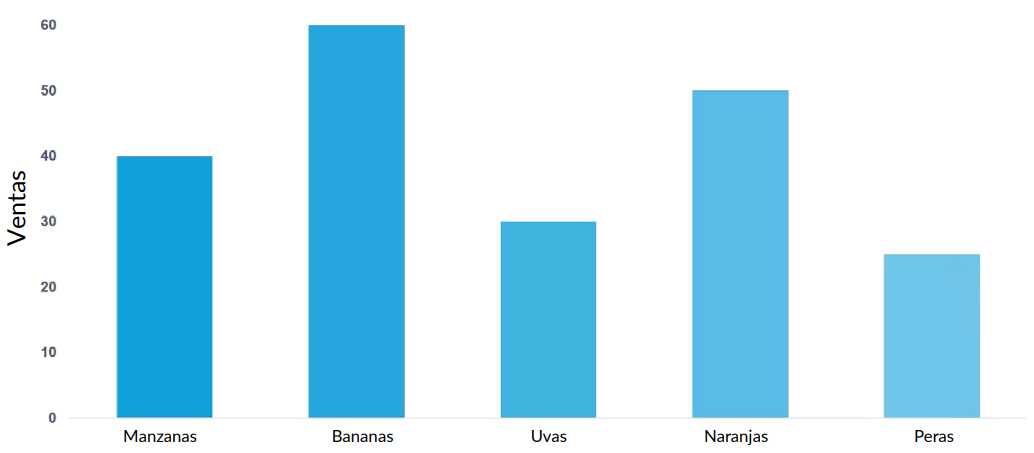
Figura 40: Ejemplo de Gráfico de Barras

Figura 41: Ejemplo de histograma
Ejemplo de Gráfico de Dispersión

Figura 42: Ejemplo de Gráfico de Dispersión
Biplots y Diagramas de Caja
Biplots
● Un Biplot es un gráfico de dispersión mejorado que utiliza tanto puntos como vectores para representar la estructura
● Un biplot utiliza puntos para representar las puntuaciones de las observaciones en los componentes principales, y utiliza vectores para representar los coeficientes de las variables en los componentes principales (Figura: Ejemplo de un biplot)
Diagramas de caja
● Un diagrama de caja o boxplot es un método para representar gráficamente grupos de datos numéricos a través de sus cuartiles
● Los gráficos de caja también pueden tener líneas que se extienden verticalmente desde las cajas (bigotes) indicando la variabilidad fuera de los cuartiles superior e inferior, de ahí los términos gráfico de caja y bigotes y diagrama de caja y bigotes. Los valores atípicos pueden representarse como puntos individuales (Figura: Ejemplo de diagrama de caja y su información clave)
Ejemplo de un Biplot
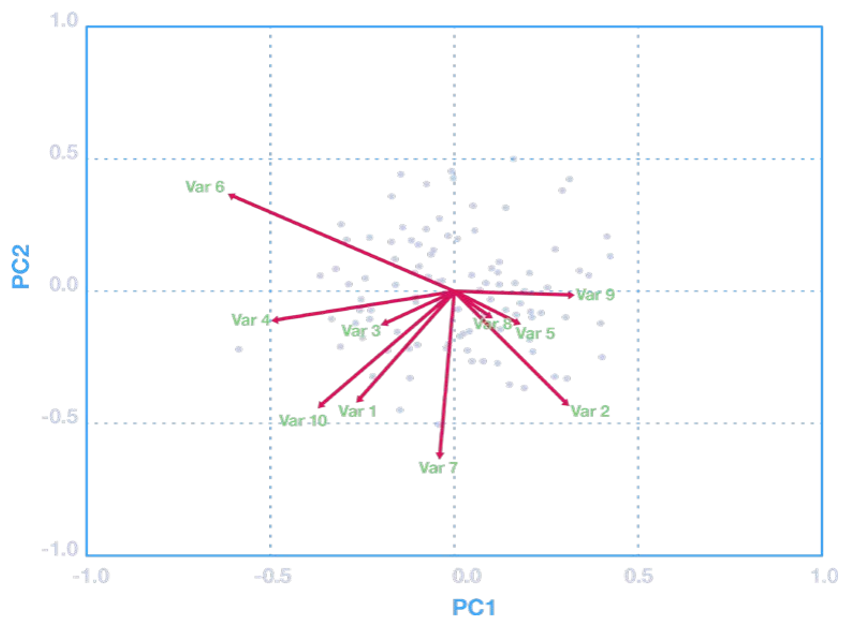
Figura 43: Ejemplo de un Biplot
Ejemplo de Diagrama de Caja y su Información Clave

Figura 44: Ejemplo de Diagrama de Caja y su Información Clave
Gráficos Q-Q
Gráficos Q-Q
● Un diagrama Q-Q (cuantil-cuantil) es un diagrama de probabilidad, que es un método gráfico para comparar dos distribuciones de probabilidad trazando sus cuantiles entre sí (Figura: Ejemplo de un diagrama Q-Q
Gráficos circulares
● Un gráfico de tarta (o gráfico circular) es un gráfico estadístico circular que se divide en rebanadas para ilustrar la proporción numérica
● En un gráfico circular, la longitud del arco de cada rebanada (y, por consiguiente, su ángulo central y su área) es proporcional a la cantidad que representa (Figura: Ejemplo de un gráfico circular)
Gráficos de radar
● Un gráfico de radar es un método gráfico de visualización de datos multivariados en forma de gráfico bidimensional de tres o más variables cuantitativas representadas en ejes que parten de un mismo punto
● La posición y el ángulo relativos de los ejes no suelen ser informativos. El gráfico de radar también se conoce como gráfico de araña debido a la naturaleza de su diseño (Figura: Ejemplo de gráfico de radar)
Ejemplo de Gráficos Q-Q

Figura 45: Ejemplo de Gráficos Q-Q
Ejemplo de un Gráfico Circular
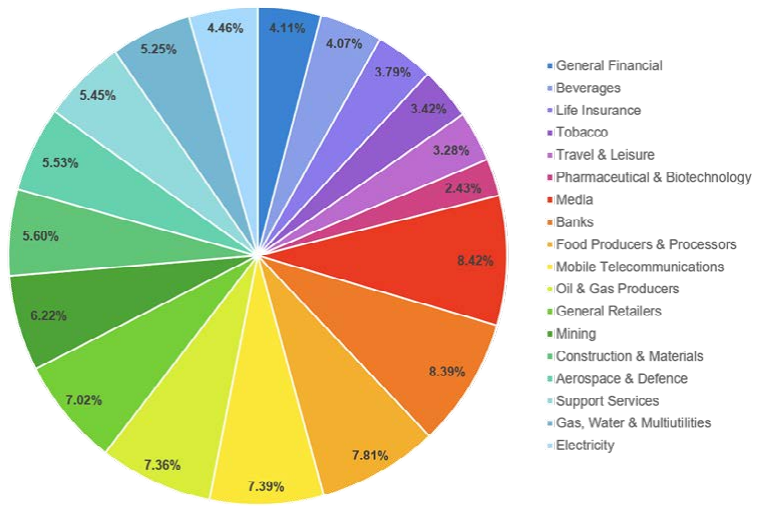
Figura 46: Ejemplo de un gráfico circular
Ejemplo de un Gráfico de Radar
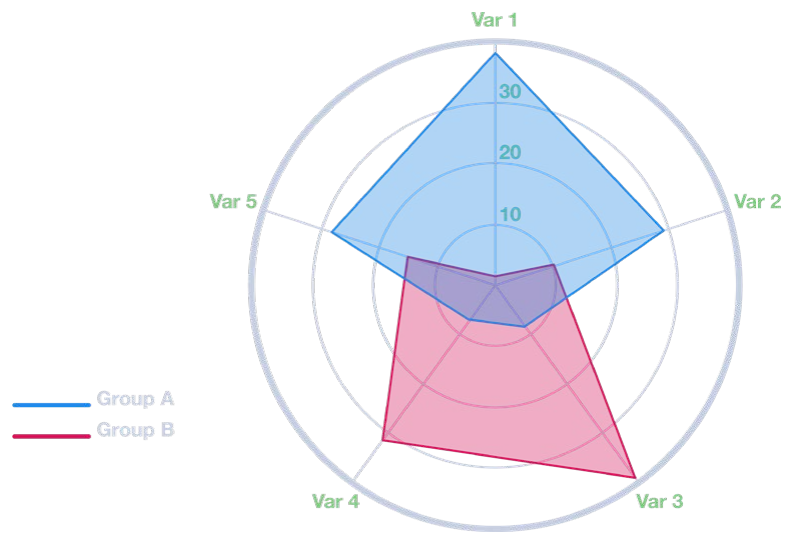
Figura 47: Ejemplo de Gráfico de Radar
Última modificación: lunes, 28 de marzo de 2022, 17:44